
Les premiers ordinateurs reconnaissent nos visages, maintenant ils savent ce que nous faisons
Par Rich McCormick,
Nous n’avons pas encore conçu une intelligence artificielle entièrement sensible, mais régulièrement nous enseignons aux ordinateurs comment voir, lire et comprendre notre monde. Le mois dernier, les ingénieurs de Google ont montré leur logiciel “Dream Deep” capable d’analyser une image et déterminer son contenue en le transformant en une sorte de cauchemar visuel où les choses se mélangent de façon psychédélique. Le nouveau logiciel de recherche des scientifiques de l’université de Stanford, qui ont développé un programme similaire appelé NeuralTalk, est capable d’analyser les images et de les décrire avec des phrases étrangement précises.
D’abord publié l’année dernière, le programme et l’étude sont le travail de Fei-Fei Li, directeur du laboratoire d’intelligence artificielle de Stanford, et Andrej Karpathy, un étudiant diplômé. Leur logiciel est capable de regarder des photos de scènes complexes et d’identifier exactement ce qu’il se passe. Par exemple une image d’un homme avec un t-shirt noir qui joue de la guitare est décrite comme “l’homme en chemise noire joue de la guitare”, tandis que des photos d’un chien noir et blanc sautant par-dessus une barre, un homme en combinaison bleue surfer une vague et une petite fille qui mange un gâteau sont également correctement décrites avec une seule phrase. Dans plusieurs cas, c’est vraiment très précis.
A computer just captioned this as “man using his laptop while his cat looks at the screen” http://t.co/bfwr1wiiFn pic.twitter.com/1F18NCwVf9
— Tim McNamara (@timClicks) 11 Juillet 2015
Comme Google’s Dream Deep, le logiciel utilise un réseau de neurones pour analyser ce qu’il se passe dans chaque image, en comparant les parties de l’image à celles qu’il a déjà vu et les décrivant comme les humains. Les réseaux de neurones sont conçus pour être comme les cerveaux humains, et ils fonctionnent un peu comme des enfants. Une fois qu’ils ont appris les rudiments de notre monde – à quoi ressemble une fenêtre, à quoi ressemble une table, ce à quoi un chat qui essaie de manger un cheeseburger ressemble – alors ils peuvent appliquer cette compréhension à d’autres photos et vidéos.
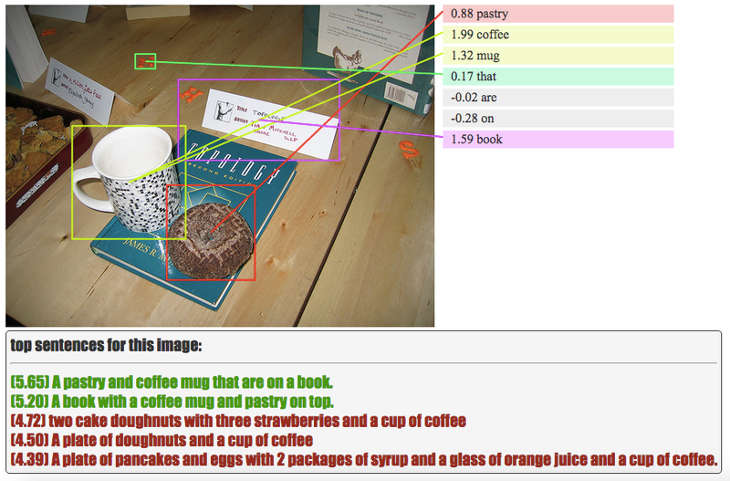
Ce n’est pas encore parfait. Une femme adulte tenant délicatement un énorme beignet est étiquetée comme “une petite fille tenant un séchoir à côté de sa tête,” tandis qu’une girafe curieuse est étiquetée comme un chien regardant par une fenêtre. Un couple dans un jardin avec un gâteau d’anniversaire apparaît sous la rubrique «un homme en chemise verte est debout à côté d’un éléphant», avec un buisson en guise d’éléphant et, bizarrement, le gâteau pour l’homme. Mais dans la plupart des cas, ces descriptions sont des suppositions secondaires – aux côtés de la suggestion de l’éléphant, le programme identifie également correctement le couple comme “une femme debout à l’extérieur tenant un gâteau à la noix de coco avec un homme qui regarde.”
La quantité incroyable d’informations visuelles sur Internet a, jusqu’à récemment, dû être marquée manuellement pour qu’elle puisse être consultée. Lorsque Google a crée Google Maps, il s’est appuyé sur une équipe d’employés pour définir et vérifier chaque entrée unique, les humains devaient vérifier chaque adresse et numéro dans le monde pour s’assurer qu’il s’agissait bien d’une adresse réelle. Quand ils ont terminer ce travail de titans, ils ont crées le cerveau de Google. Quand il fallait plusieurs semaines de travail pour compléter une tâche, le cerveau de Google pouvait retranscrire toutes les données Street View de la France en moins d’une heure.
«Je considère les données de pixels dans les images vidéos comme la matière noir de l’Internet”, a déclaré Li Le au New York Times l’an dernier. «Nous commençons maintenant à éclairer.” Les géants du Web tels que Facebook et Google sont désireux de classer les millions de photos et résultats de recherche dont ils ont besoin pour un apprentissage. Des recherches antérieures se sont concentrées sur la reconnaissance d’objet unique – dans une étude en 2012, un ordinateur apprenait seul à reconnaître un chat – mais les scientifiques ont dit qu’il manque le tableau d’ensemble. «Nous avons mis l’accent sur les objets, et nous avons ignoré l’interprétation,” Ali Farhadi, chercheur en informatique à l’université de Washington, a déclaré au New York Times.

Mais des programmes plus récents ont mis l’accent sur les chaînes de données plus complexes dans une tentative d’enseigner aux ordinateurs ce qu’il se passe dans une image plutôt que de simplement décrire la photo. L’étude des scientifiques de Stanford utilise le genre de langage naturel que nous pourrions éventuellement utiliser pour effectuer des recherches à travers des répertoire d’image, menant à une situation hypothétique facile où plutôt que de balayer à travers des dizaines de milliers de photos de famille, des services tels que Google Photos peuvent rapidement remonter “celle où le chien saute sur le canapé », ou « le selfie que j’ai pris à Times Square “. Les résultats de recherche pourraient bénéficier de la technologie vous permettant de rechercher sur YouTube ou Google des scènes exactes que vous voulez, plutôt que de trouver simplement les photos ou vidéos des personnes qui étaient assez soucieux pour étiqueter correctement.
Les réseaux de neurones ont aussi des applications potentielles dans le monde réel. Au CES de cette année, Jen-Hsun Huang de Nvidia a annoncé Drive PX, un “superordinateur” pour votre voiture qui intègre une “profonde vision du réseau neuronal de l’ordinateur.” En utilisant les mêmes techniques d’apprentissage que les autres réseaux de neurones, Huang a dit que la technologie sera en mesure de repérer automatiquement les dangers lorsque vous conduisez, vous avertissant des piétons, des panneaux, des ambulances, et d’autres objets qu’il a appris. Les moyens de réseau neuronal de Drive PX n’a pas besoin d’avoir des images de référence pour chaque type de voiture – si il y a quatre roues comme une voiture, une calandre comme une voiture et un pare-brise comme une voiture, alors c’est probablement une voiture. Les grosses voitures pourraient être des SUV, tandis que les voitures avec des gyrophares sur le dessus pourraient être des véhicules de police. La compagnie de Huang connaît cette technologie depuis un certain temps, elle a fourni des données qui sont actuellement utilisées par l’équipe de Stanford.

Comme la technologie d’interprétation automatique de ce qui se passe dans les images progresse rapidement, ses dirigeants rendent leurs efforts accessibles à tous sur des référentiels de code tels que GitHub. Google Dream Deep, en particulier, a capturé l’imagination de beaucoup avec ses effets visuels psychédéliques, tordant des images dans des formes de chiens et de limaces, car il tente de trouver des points de référence qu’il comprend. Mais la prolifération de cet apprentissage de la machine a aussi un côté effrayant – si votre ordinateur peut déterminer exactement ce qui se passe dans vos photos, que se passera-t-il quand il déterminera exactement ce que vous êtes ?
Source : The Verge


















