
Un « décodeur cérébral » qui transforme l’activité neuronale en parole
Le futur est déjà là : des scientifiques ont dévoilé un nouveau décodeur qui synthétise la parole d’une personne à l’aide de signaux du cerveau associés aux mouvements de la mâchoire, du larynx, des lèvres et de la langue.
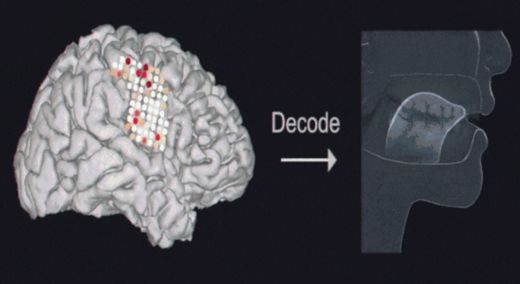
Cela pourrait changer la donne pour les personnes souffrant de paralysie, de troubles de la parole ou de troubles neurologiques.
Pour la plupart d’entre nous, le processus de la parole, que nous tenons pour acquis dans notre vie de tous les jours, est en fait très complexe, très difficile à « numériser ».
Selon les chercheurs :
Il faut une coordination précise et dynamique des muscles des structures articulatrices des voies vocales : les lèvres, la langue, le larynx et la mâchoire.
Décomposer la parole en ses parties constitutives ne fonctionne pas vraiment. L’orthographe, si vous y pensez, est une concaténation séquentielle de lettres discrètes, alors que la parole est une forme de communication très efficace impliquant un flux fluide de mouvements complexes et se chevauchant, et les modèles d’activité du cerveau associés à ces mouvements sont également complexes.
La première étape consistait à enregistrer l’activité corticale du cerveau de 5 participants. L’activité cérébrale de ces volontaires a été enregistrée alors qu’ils prononçaient plusieurs centaines de phrases à voix haute. Les mouvements de l’appareil/ tractus vocal ont également été suivis. Ensuite, les scientifiques ont procédé à la rétro-ingénierie du processus, à l’inverse, produisant la parole à partir de l’activité cérébrale. Lors de tests de 101 phrases, les auditeurs pouvaient facilement identifier et transcrire le discours synthétisé.

Un exemple de réseau d’électrodes intracrâniennes du même type utilisé pour enregistrer l’activité cérébrale dans la présente étude. (UCSF)
Plusieurs études ont utilisé des méthodes d’apprentissage profond pour restituer des signaux audio à partir de signaux cérébraux, mais dans cette étude, une équipe dirigée par Gopala Anumanchipalli, a tenté une approche différente. Ils divisent le processus en deux étapes : l’une qui décode le mouvement associé à la parole et l’autre qui synthétise la parole. Le discours a été diffusé à un autre groupe de personnes, qui n’avaient aucun problème de compréhension.
Dans des tests distincts, les chercheurs ont demandé à un participant de prononcer des phrases, puis de mimer le discours (en faisant les mêmes mouvements que s’il parlait, mais sans le son). Ce test a également été couronné de succès, les auteurs concluant qu’il est possible de décoder certaines caractéristiques de la parole qui ne sont jamais prononcées de façon audible.
Animation du tractus vocal simulé (Chang Lab/ Département de neurochirurgie de l’UCSF/ Speech Graphics) :
La vitesse à laquelle la parole était produite fut également remarquable. Perdre la capacité de communiquer en raison d’une pathologie est dévastateur. Les appareils qui utilisent les mouvements de la tête et des yeux pour sélectionner les lettres une par une (système utilisé par feu l’astrophysicien Stephen Hawking) peuvent aider, mais ils produisent environ 10 mots/minute, beaucoup plus lent que la moyenne de 150 mots/minute d’un débit de parole moyen. Cette nouvelle technologie est comparable au débit naturel de la parole, marquant une amélioration spectaculaire.
Il est important de noter que cet appareil n’essaie pas de comprendre ce que quelqu’un pense, seulement d’être capable de produire de la parole.
Edward Chang, l’un des auteurs de l’étude, explique :
Le laboratoire n’a jamais cherché à savoir s’il est possible de décoder ce qu’une personne pense à partir de son activité cérébrale. Le travail du labo est uniquement axé sur le rétablissement de la capacité de communication des patients atteints de troubles de la parole.
Bien qu’il s’agisse encore d’une preuve de concept et qu’il reste encore beaucoup de travail à faire avant qu’elle puisse être mise en œuvre dans la pratique, les résultats sont probants. Avec des progrès continus, les personnes atteintes de troubles de la parole auront bientôt les moyens de retrouver la capacité de dire ce qu’elles pensent et de renouer le contact avec le monde qui les entoure.
L’étude publiée dans Nature : Speech synthesis from neural decoding of spoken sentences et présentée sur le site de l’université de Californie à San Francisco : Synthetic Speech Generated from Brain Recordings.
Lire aussi : Elon Musk : Une machine Neuralink reliant le cerveau humain à des ordinateurs et donc l’IA va bientôt voir le jour
Source : GuruMeditation














