
Deepfake : des chercheurs présentent un logiciel qui permet d’éditer le discours d’une vidéo et faire dire au sujet ce que vous voulez
Un deepfake est une technique de synthèse d’images basée sur l’intelligence artificielle.

Il est utilisé pour combiner et superposer des images et des vidéos existantes afin de les manipuler à l’aide de l’apprentissage automatique. La technologie est en développement et des chercheurs continuent d’améliorer les méthodes qui contribueront certainement à révolutionner certains secteurs d’activité mais qui ne manqueront, peut-être, pas de se retrouver, comme une arme, entre les mains des personnes malveillantes.
Dans le dernier exemple en date traitant de la technologie deepfake, des chercheurs ont présenté un nouveau logiciel qui utilise l’apprentissage automatique pour permettre aux utilisateurs de modifier la transcription du texte d’une vidéo afin d’ajouter, de supprimer ou de modifier les mots sortant de la bouche de quelqu’un.
Le travail a été effectué par des scientifiques de l’Université de Stanford, de la Max Planck Institute for Informatics, de l’Université de Princeton et d’Adobe Research. Il montre que notre capacité à éditer ce que les gens disent dans des vidéos et à créer des faux réalistes devient chaque jour plus facile.
Vous pouvez voir ci-dessous un certain nombre d’exemples de sortie du système. Dans le premier, nous voyons une femme dire « qu’Apple a clôturé le marché avec des actions à 191,45 dollars ». L’orateur explique alors qu’ils ont remplacé 91,4 par 82,2. La vidéo modifiée montre la même femme qui dit « qu’Apple a clôturé le marché avec des actions à 182,25 dollars » avec un changement dans la façon de bouger les lèvres.
Ce travail est juste au stade de la recherche en ce moment et n’est pas disponible en tant que logiciel grand public, mais il ne faudra probablement pas longtemps avant que des services similaires ne deviennent publics. Adobe, par exemple, a déjà partagé des détails sur le prototype de logiciel appelé VoCo, qui permet aux utilisateurs de modifier des enregistrements de parole aussi facilement qu’une image, et qui a été utilisé dans cette recherche.
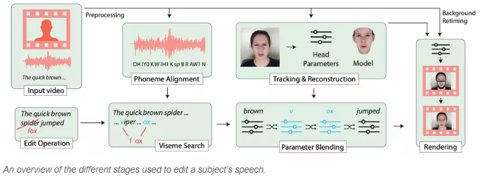
Pour créer les contrefaçons vidéo, les scientifiques combinent un certain nombre de techniques. Tout d’abord, ils numérisent la vidéo cible pour isoler les phonèmes parlés par le sujet. (ce sont des élément sonore du langage parlé, considéré comme une unité distinctive, par exemple le phonème /i/ dans il ou le phonème /p/ : père). Ils associent ensuite ces phonèmes aux visèmes correspondants, qui sont les expressions faciales accompagnant chaque son. Enfin, ils créent un modèle 3D de la moitié inférieure du visage du sujet en utilisant la vidéo cible.
Lorsque quelqu’un édite une transcription textuelle de la vidéo, le logiciel combine toutes les données collectées (phonèmes, visèmes et modèle de visage 3D) pour créer un nouveau métrage qui correspond au texte saisi. Par la suite, cet ensemble est collé sur la vidéo source pour créer le résultat final.
Lors de tests dans lesquels les vidéos éditées par l’utilisation du deepfake ont été montrées à un groupe de 138 volontaires, environ 60% des participants ont pensé que les modifications étaient réelles. Les chercheurs ont noté que cela pourrait être dû au fait que les personnes concernées ont été informées que leurs réponses étaient utilisées pour une étude sur le montage vidéo, ce qui signifie qu’elles étaient prêtes à rechercher des contrefaçons.

Comme toujours, il est important de se rappeler que ce que cette technologie peut faire est limité
Les algorithmes ici ne fonctionnent que sur des vidéos où on ne voit que la tête de la personne qui parle, par exemple, et nécessitent 40 minutes de données en entrée. Le discours édité semble ne pas devoir être trop éloigné du matériel source. Les chercheurs ont alors demandé aux sujets d’enregistrer un nouveau son pour correspondre aux changements, en utilisant l’IA pour générer la vidéo. (Ceci est dû au fait que les contrefaçons audio sont parfois médiocres, bien que la qualité s’améliore nettement). D’ailleurs, pour les vidéos générées par l’IA, 80% du groupe de participants ont pensé qu’elles étaient réelles.
Les chercheurs ont également noté qu’ils ne pouvaient pas encore changer l’ambiance ou le ton de la voix de l’orateur, car cela entraînerait « des résultats étranges ». Et que toute occlusion du visage, par exemple. si quelqu’un agite la main en parlant, va complètement perdre l’algorithme.
La technologie n’est donc pas parfaite, mais ces types de limitations figurent toujours dans les premières étapes de la recherche et il est presque garanti qu’elles seront surmontées à temps. Cela signifie que la société dans son ensemble devra bientôt s’attaquer au concept sous-jacent de cette recherche: l’arrivée d’un logiciel qui permet à quiconque d’éditer ce que les gens disent dans des vidéos sans formation technique.
Les inconvénients potentiels de cette technologie sont extrêmement préoccupants et les chercheurs dans ce domaine sont souvent critiqués pour ne pas avoir pris en compte le potentiel d’utilisation abusive de leurs travaux. Les scientifiques impliqués dans ce projet précis ont déclaré avoir pris en compte ces problèmes.
Dans un billet de blog accompagnant l’article, ils écrivent : « Bien que les méthodes de manipulation d’images et de vidéos soient aussi anciennes que les médias eux-mêmes, les risques d’abus sont accrus lorsqu’ils sont appliqués à un mode de communication qui est parfois considéré comme une preuve de pensée et les intentions. Nous reconnaissons que de mauvais acteurs pourraient utiliser de telles technologies pour falsifier des déclarations personnelles et calomnier des personnalités ».
Mais le garde fou qu’ils suggèrent n’est guère réconfortant. Selon eux, pour éviter toute confusion, les vidéos éditées par IA devraient être clairement présentées comme telles, soit par le biais d’un filigrane, soit par le biais d’un contexte (par exemple, un public qui comprend qu’il regarde un film de fiction).
Mais les filigranes sont facilement supprimés et la perte de contexte est l’une des caractéristiques des médias en ligne. Les fake news n’ont pas besoin d’être irréprochables pour avoir un impact non plus. Il suffit de quelques minutes de recherche pour dissiper une foule de fake news traitant de l’actualité, mais cela n’arrête pas pour autant leur propagation, en particulier dans les communautés qui veulent croire de telles messages véhiculés qui correspondent à leurs idées préconçues.
Les chercheurs notent que cette technologie présente également de nombreux avantages. Cela aiderait beaucoup les industries du cinéma et de la télévision, leur permettant de corriger les lignes mal prononcées sans passer par un réenregistrement des images et de créer des doublages sans faille d’acteurs parlant différentes langues.
Mais ces avantages sont-ils suffisant pour contrebalancer les dégâts potentiels ?
Lire aussi : Une nouvelle IA permet de créer de fausses vidéos à partir d’une seule photo
Sources : Developpez.com par Stéphane le calme – blog des chercheurs, présentation de la recherche (au format PDF)














